雖然GPT可以像BERT一樣利用起始與結尾進行訓練,但這樣會讓今天的內容顯得無趣,因此我將用ChatGPT的概念讓GPT-J在閱讀完SQuAD的文章後進行推理並得出答案,不過今天我們訓練的ChatGPT的模型參數量實在太大,所以我會教你該如何微調大型語言模型,並探討GPT如何生成這些文字的方式,今天的學習重點如下:
LoRA技術簡介PEFT函式庫的安裝與使用GPT-J實作與生成在微調大型語言模型時我們一定會遇到一個問題也就是**GPU的記憶體不夠大!!!**所以我們再調整模型使往往要用到更多張的GPU或是一些特殊的方法,而在今天因為我們要使用的GPT-J是擁有60億的參數的大型語言模型,這使得我們就算用24GB記憶體的RTX 3090顯卡進行訓練,也無法將它和訓練數據同時放入GPU進行運算,當然解決策略並不是投資在更多昂貴的顯示卡上,而是用LoRA(Low-Rank Adaptation)這項技術來幫助我們解決這個問題。
LoRA這項技術的主要理念是在我們微調模型時,將每一層的輸出都定義為原始權重W加上更新的權重ΔW(h = Wx + ΔW),而在微調模型的目標就是要計算出ΔW的數值,但我們在求取ΔW的值需經過前向與反向傳播的計算,因此需要花費更多的記憶體空間去追蹤這些梯度的操作,並且在訓練時間也會增加,所以作者大膽地提出可以訓練一個體積更小的可訓練權重(Trainable Weight)來省去一些複雜計算的步驟。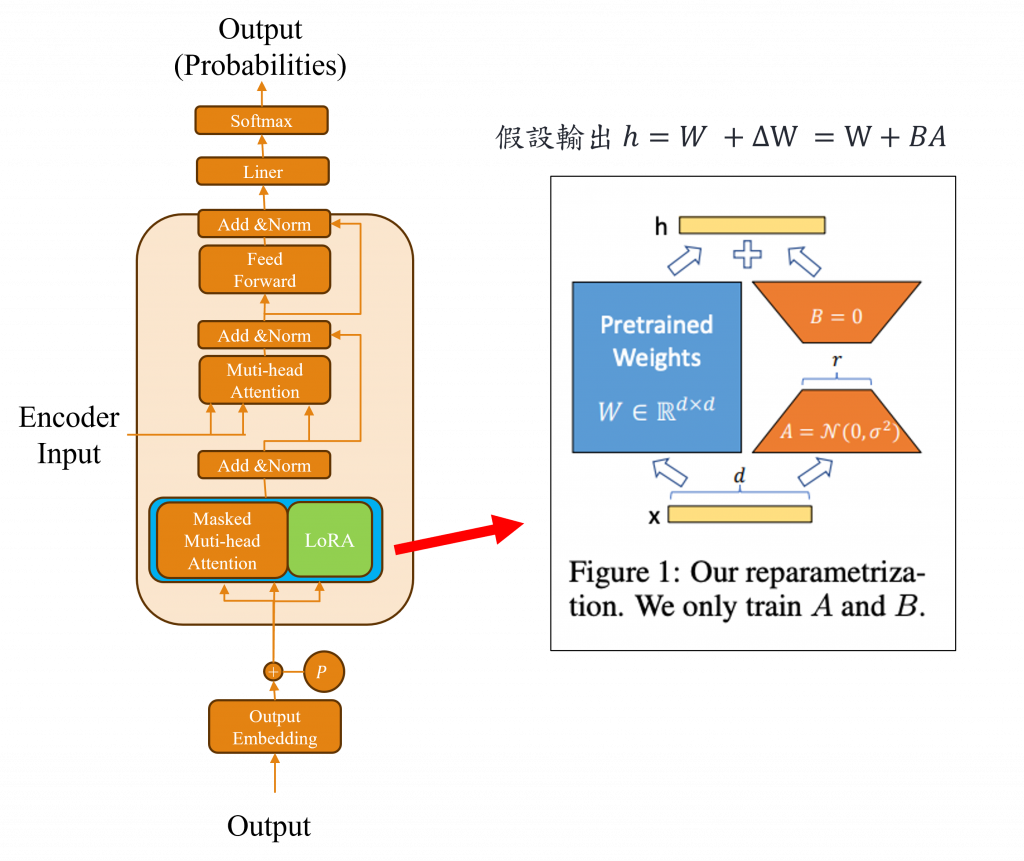
基於這個原理在LoRA所採取的策略是利用近似低秩矩陣(Low-Rank Matrix Approximation)來降低原始層權重W並通過這個近似低秩矩陣求出新的答案,同時將部分的層數凍結防止進行反向傳播,同時因模型使用的是32bit來建立的,所以其記憶體使用率較高,因此在這個過程中還能將資料型態轉換為8bit以大幅縮小模型的大小。最後在建立完畢近似低秩矩陣後,我們還需要建立特定層的權重矩陣B,這樣子讓在模型進行前向傳播時僅需運算BA,就可取代大量的運算。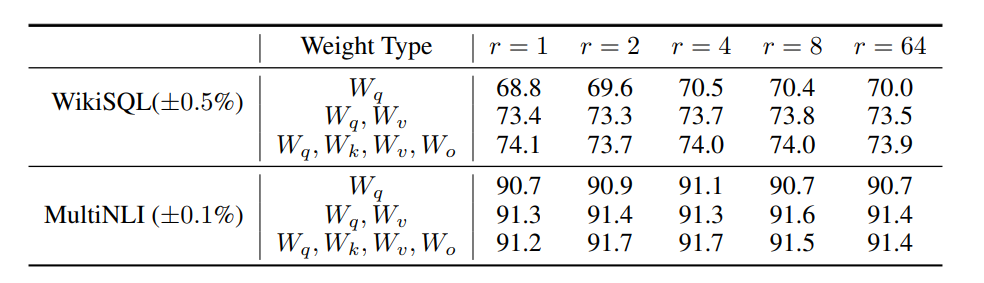
而根據實驗結果LoRA的效果甚至比傳統微調更出色,而對於這些大型語言模型的Transformer架構最需要LoRA的部分是Muti head attention的q、k、v、和o層,在上圖揭示了attention向量的q、k、v、o以及進行降維的r(Rank)與模型效能之間的相關性。
現在你已經懂了LoRA的技術員裡,所以我將教你如何利用這項技術來完成我們今天的QA任務。而在程式中我們需要通過Hugging Face打造的PEFT函式庫,這個函式庫已經完美包裝了大型語言模型的LoRA方式,使我們能夠大幅縮短程式撰寫時間,接下來就讓我門看看該如何使用它來微調GPT-J吧!
在PEFT中需要使用非常多的相關函式庫,雖然官方有提供範例供我們參考,但這些函式庫卻多數與最新版的Pytorch和Windows不相符,因此我們首要的任務是確認自己的Pytorch版本是否低於CUDA 11.6版,這是因為在相關函式庫中bitsandbytes只支援到CUDA 11.6版。
雖然我們可以不安裝它,但這個函式庫的重要性不容忽視,它能夠幫我們把模型從32bit轉換成8bit,若版本確實低於CUDA 11.6,我們只需要直接輸入以下的pip指令即可,如此Windows版本的PEFT安裝便告一段落。
pip install -q accelerate loralib jmespath
pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git
pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui
不過若你是Mac或是linux的用戶你需要輸入下方的指令才能夠正常安裝。
pip install -q accelerate loralib jmespath
pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git
pip install -q bitsandbytes

下載GPT-J的方法我們同樣的可以從Hugging Face網站來取得,而我們可以到這個連結中,搜尋GPT-J來找到最適合你的版本,而這次我們以最初的版本gpt-j-6B進行訓練。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-j-6B",
load_in_8bit=True,
device_map='auto',
)
在程式中我們只需輸入模型的名稱即可透過API下載該模型。但必須記住我們必須在參數上要加上load_in_8bit=True,如此模型才能被轉換成8 bit,同時我們需要使用device_map='auto'來自動指派模型被傳入的GPU設備。
現在我們已將模型架構轉換成8bit型態,並且當前的資料型態為float32,而我們可以通過轉換型態的方式來增加訓練速度,因此我們可以透過model.parameters()讀取所有的參數,同時關閉梯度追蹤功能以凍結它們的權重。
for param in model.parameters():
param.requires_grad = False
if param.ndim == 1:
param.data = param.data.to(torch.float16)
接下來我們需要使用gradient_checkpointing_enable來減少記憶體的使用量,並且使用enable_input_require_grads讓模型的Embedding層能夠更適合當前的任務,尤其是我們有加入Special token時更需要開啟enable_input_require_grads。
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
最後我們需要修改模型的輸出層,因為該層並非模型本身的一部分,而是在微調階段時才加入的,所以我們需要單獨去修改它,而今天我們需要修改的最後一層,你可以透過以下的程式碼找到該層參數的名稱。
print(model)
# --------------輸出----------
PeftModelForCausalLM(
(base_model): LoraModel(
.
.
.
(lm_head): CastOutputToFloat(
(0): Linear(in_features=4096, out_features=50400, bias=True)
)
)
)
)
此時我們可以明瞭lm_head在程式中即為模型的輸出,在這裡修改它的方法需重新建立一個繼承了lm_head的子類,並將其修改為float16的形式即可。
class CastOutputToFloat(nn.Sequential):
def forward(self, x): return super().forward(x).to(torch.float16)
model.lm_head = CastOutputToFloat(model.lm_head)
在PEFT的函式庫中我們只需要透過LoraConfig()來設定r、lora_alpha以及target_modules等參數,即可於指定層數添加LoRA的功能,而這次我主要針對Attention中的q、v向量進行運算,因此我則選擇了q_proj與v_proj作為微調的部分,若你有其他想要訓練的層數你可以通過print(model)來找出這些參數的名稱。
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
接下來我們可以使用下列的程式來計算模型經過LoRA後,來看看剩餘的參數總數。
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
print_trainable_parameters(model)
# ----------輸出----------
trainable params: 7340032 || all params: 6058222816 || trainable%: 0.12115817167725645
可以看到當我們使用LoRA後模型的參數量只剩下原來的0.12%,因此我們在運算時就不需要使用到太大的記憶體空間。
我們同樣使用json函式庫來讀取資料,不過在資料整理方面有些許不同,這次我們不僅要加入先前未能訓練的is_impossible問答,還需要將其轉換成prompt的輸入格式。
import json
def load_json_data(path):
with open(path) as f:
json_data = json.load(f)
return json_data['data']
json_datas = load_json_data('data/train-v2.0.json')
在資料處理時我們這邊對context、answer與question前方加入了一個前綴,因為我希望模型能透過這個前綴來識別他們本身的含意,接下來我還加入了一個instruction(指令)Read the context and question to find the correct answer來告知模型它現在該做的事情。
from sklearn.model_selection import train_test_split
train_data = []
for json_data in json_datas:
paragraphs = json_data['paragraphs'][0]
context = paragraphs['context']
qas = paragraphs['qas']
for qa in qas:
question = qa['question']
if qa['is_impossible']:
answer = 'answers not in context'
else:
answer = qa['answers'][0]['text']
output = f'Read the context and question to find the correct answer:\n context:{context} question:{question}\nanswer:{answer}'
train_data.append(output)
x_train, x_valid = train_test_split(train_data, train_size=0.8, random_state=46, shuffle=False)
接下來因為我們在GPT-J中並沒有填充的詞彙,所以我們必須自行加入這個詞彙,不然我們在使用tokenizer()進行轉換時就會沒有這個詞彙而填充錯誤,而在這裡我直接將文字的結尾eos_token來替代這個詞彙。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
tokenizer.pad_token = tokenizer.eos_token
在這裡我們不會先進行文字的處理,這主要是因為我們將在collate_fn中直接使用tokenizer來執行填充和設定標籤的操作,而對於GPT-J這種基於Decoder的模型來說輸入會有input_ids、attention_mask等參數(如果你忘記可以回到Day 23查看),而他們所對應的標籤就是input_ids,因為我們在訓練時就是使用Teacher Forcing的方法(Day 9),但請注意,這次我們不使用pin_memory參數,這是因為該參數會將數據固定在記憶體中讓記憶體的需求更大。
from torch.utils.data import Dataset, DataLoader
import torch
def collate_fn(batch):
x = list(batch)
x = tokenizer(x, truncation=True, padding="longest", return_tensors='pt')
return {**x, 'labels':x.input_ids}
class QAdataset(Dataset):
def __init__(self, x):
self.x = x
def __getitem__(self, index):
return self.x[index]
def __len__(self):
return len(self.x)
trainset = QAdataset(x_train)
validset = QAdataset(x_valid)
train_loader = DataLoader(trainset, batch_size = 8, shuffle = True, num_workers = 0, collate_fn = collate_fn)
valid_loader = DataLoader(validset, batch_size = 8, shuffle = True, num_workers = 0, collate_fn = collate_fn)
在tokenizer的部分,我們需要特別注意的是truncation=True這個參數,如果我們沒有設定此參數,詞彙在轉換時可能會超過模型的最大輸入1024,而padding="longest"則是用來進行截長補短的操作。如果你的GPU記憶體不夠大,可以考慮將padding='longest'改為padding='inputs_text',並設定max_length=你想要的長度以解決記憶體不足的問題,但這樣的設定可能會導致模型的結果變差,因此如果GPU記憶體夠大的話,建議還是直接使用padding="longest"。
這段訓練模型的程式碼我想大家看過了很多次,而這次甚至與【Day 23】因為站在巨人的肩膀上才能眺望更遠的風景(下)-使用SQuAD做QA問答中的【STEP 6】到【STEP 7】完全相同,因此我在此不再重覆撰寫,你可以直接點選該連結或至GitHub查看訓練的程式碼。
Train Epoch 0: 100%|██████████| 386/386 [11:40<00:00, 1.81s/it, loss=1.146]
Valid Epoch 0: 100%|██████████| 97/97 [00:45<00:00, 2.12it/s, loss=1.303]
Saving Model With Loss 1.36042
Train Loss: 1.31501| Valid Loss: 1.36042| Best Loss: 1.36042
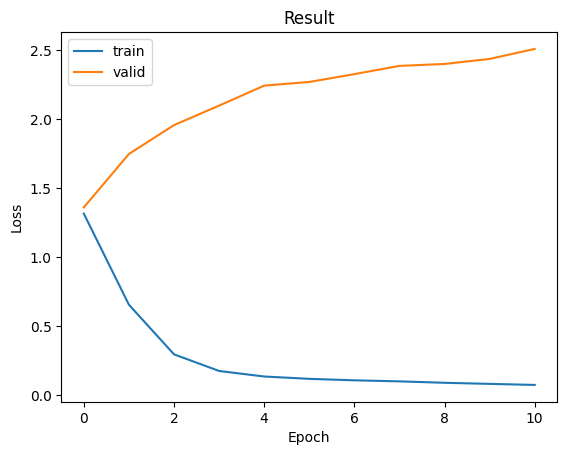
從模型的最終訓練結果來看,我們可以觀察到在完成第一次訓練後就直接出現了Overfitting的情況,這種情形比我們在使用BERT模型時還要嚴重,因為在大型語言模型中有非常強大的權重,因此在輸入資料較小的狀況下,模型的收斂就會非常快。
那我們該怎麼使用模型進行文字生成的動作呢?在這裡我們不必自己撰寫解碼的程式,因為在該模型中已經定義了一個generate()方法,在這邊我列出一些我常使用的參數與其概念,我們可以看到下表:
| 名稱 | 說明 |
|---|---|
| num_beams | 每次生成文字時有多少個選項,並根據設定挑選結果 |
| max_length | 生成文本最大長度 |
| repetition_penalty | 控制重複詞彙的懲罰力度,數值越高重複詞會出現次數越低 |
| early_stopping | 是否在達到生成文本的最大長度時就停止生成 |
| length_penalty | 平衡生成文本的長度,1.0 表示對生成文本的長度不進行任何調整 |
接下來我們就可以調整參數,並將文字放入模型中使模型推理並給出回應,在這裡我們需要將訓練時的instruction和answer兩部分去除,並將其轉換成input_ids這樣模型就能進行zero-shot的推理了。
inputs_text = "".join(x_valid[0][54:].split('answer:')[:-1])
input_ids = tokenizer(inputs_text, return_tensors="pt")
generated_ids = model.generate(**input_ids, num_beams = 2, max_length = 132, repetition_penalty = 2.5, length_penalty = 1.0, early_stopping = True)
當完成之後我們只需將生成的數字轉換成文字就可以看到其推理的結果了。
generated_tokens = tokenizer.decode(generated_ids[0], skip_special_tokens=True).split('answer:')
print(generated_tokens[0])
print(generated_tokens[1])
print(x_valid[0].split('answer:')[2])
#--------輸出--------
context:A railway electrification system supplies electric power to railway trains and trams without an on-board prime mover or local fuel supply. Electrification has many advantages but requires significant capital expenditure. Selection of an electrification system is based on economics of energy supply, maintenance, and capital cost compared to the revenue obtained for freight and passenger traffic. Different systems are used for urban and intercity areas; some electric locomotives can switch to different supply voltages to allow flexibility in operation. question:A railway electrification system supplies power to trains and trams with an on-board what?
answers not in context
answers not in context
而我們可以看到,即使答案並不存在於文章當中仍能觀察到GPT-J能夠優秀地判別並產出最終結果,這是因為GPT-J在預訓練的過程中已經得到了有效的訓練讓它的表現出色,當然我們還可以增加更多的prompt或few-shot進行測試,這使得模型能生成出更佳的效果。
今天是我們首次學習大型語言模型,但有些人即便使用LoRA的技術來微調,電腦可能仍然承受不了壓力,在這種情況下,我們可以轉用GPT-2模型來體驗今天的程式,雖然效能有差但是在概念上卻是差不多的。
而我們要學習這些的原因是因為ChatGPT的出現,而它的強大性能是有目共睹的,所以現今的自然語言處理的最新研究方向,就是繞者大型語言模型來進行的。而在後續的內容中我將持續解釋大型語言模型的理論與應用,並且在接下來的一兩天,我將會教你如何使用ChatGPT讓它成為你的助手。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽